前言: gitlab使用CICD触发本地AI模型审核代码与代码提交页面评论
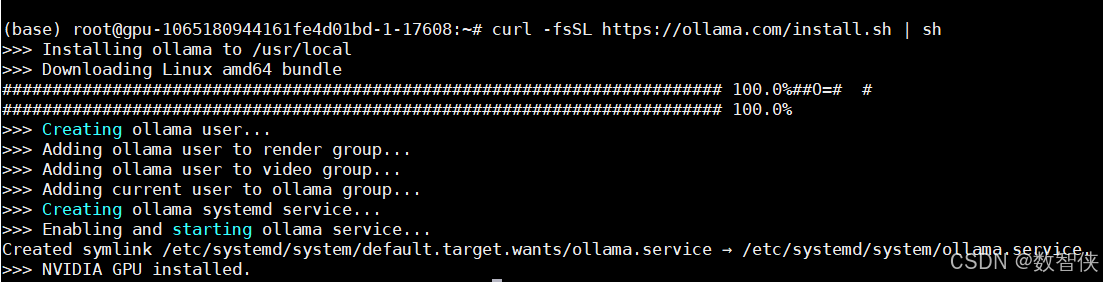
安装ollama+open-webui ,这是linux安装,此步骤百度即可,安装简单
curl -fsSL https://ollama.com/install.sh | sh
 如果访问出现404则需要多次重试,或者使用代理方式
如果访问出现404则需要多次重试,或者使用代理方式
ollama的简单使用
# 下方是检验是否安装成功 [root@localhost ~]# ollama Usage: ollama [flags] ollama [command] Available Commands: serve Start ollama create Create a model from a Modelfile show Show information for a model run Run a model stop Stop a running model pull Pull a model from a registry push Push a model to a registry list List models ps List running models cp Copy a model rm Remove a model help Help about any command Flags: -h, --help help for ollama -v, --version Show version information Use "ollama [command] --help" for more information about a command. # 命令简单说明 ollama ps 查看正在运行的模型 ollama list 查看已经下载的模型列表 ollama help 查看ollama相关命令 # 下载并运行模型,下载比较久,需要等待一段时间,模型可去官网查看适合自己使用的 [root@localhost ~]# ollama run llama3:8b # 由于本地已经已经安装好模型,网上找一下其他模型的安装过程 # 然后后的ollama 默认会自动启动以及配置开机自启,如果需要重启等使用systemctl restart ollama(可选)修改ollama网络
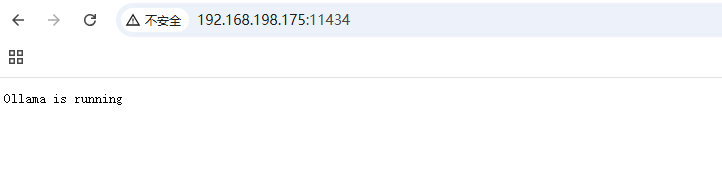
# 如果open-webui不与ollama安装一起则需要按照下方步骤修改 vim /etc/systemd/system/ollama.service # 请在[Service] 下面添加 Environment="OLLAMA_HOST=0.0.0.0" # 重启重新绑定 sudo systemctl daemon-reload sudo systemctl restart ollama # 然后浏览器访问机器ip+11434 检查是否正常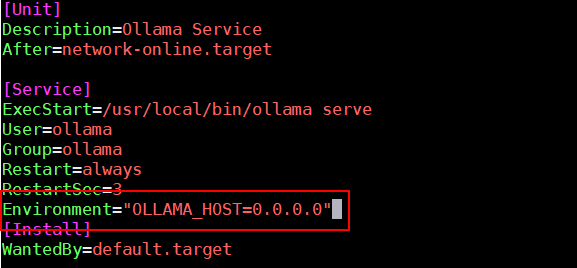
open-webui 安装,为了省麻烦使用docker简单安装
# docekr 镜像拉取比较慢,需要等待,或者自己寻找国内镜像 docker run -d -p 3000:8080 -e OLLAMA_BASE_URL=http://192.168.198.175:11434 -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main # 运行成功则可以访问docekr 所在机器 ip+3000 访问open-webui # 然后再访问后会出现登入与注册的页面,点击进入注册,邮件就是以后的登入名字,要记住邮件与密码,还有这个不用验证电子邮件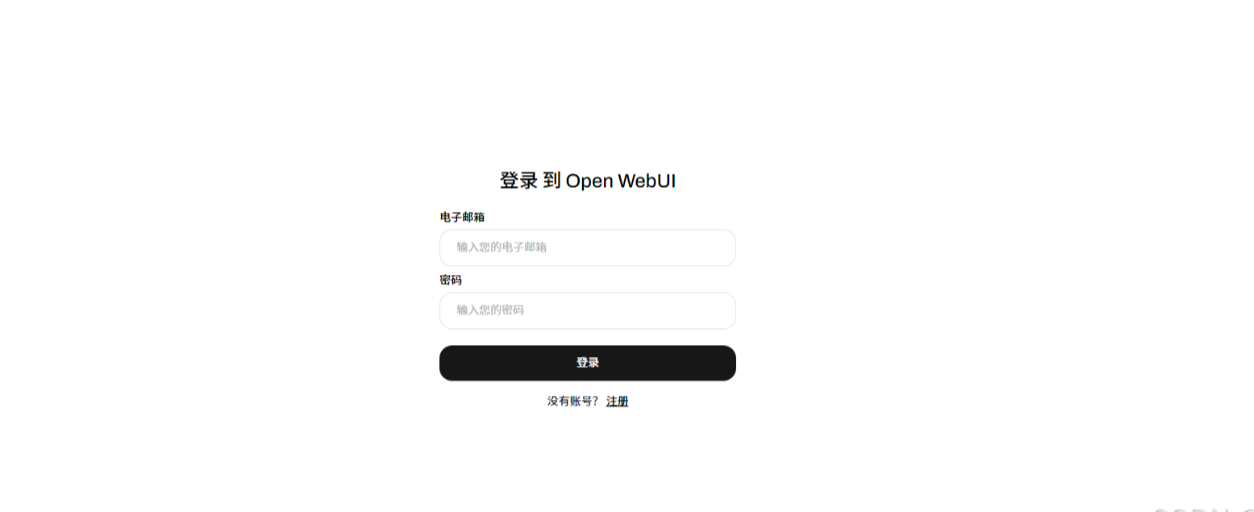
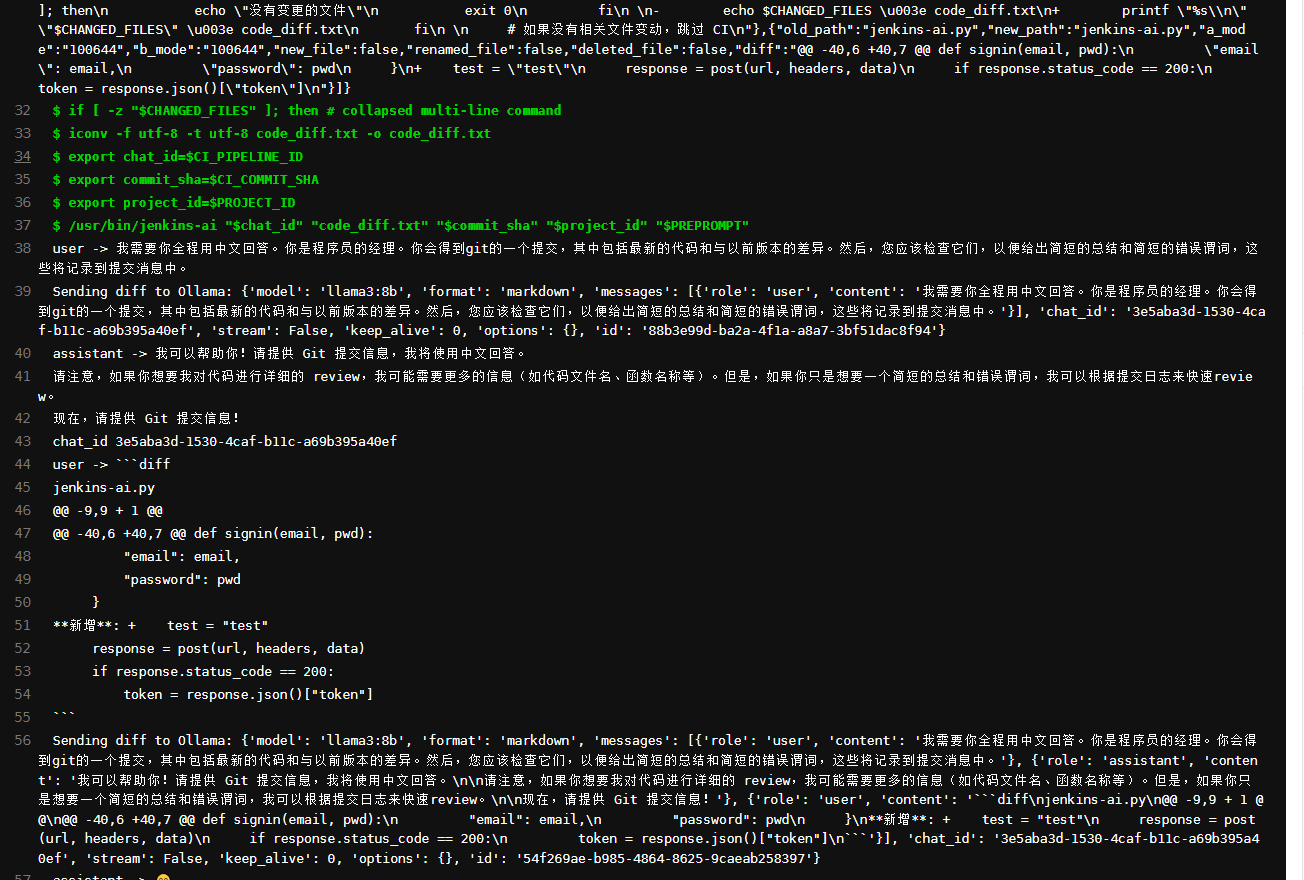
下方是处理逻辑代码,由于我是在linux环境使用pyinstall 制作成二进制执行文件,所以把gitlab的token封装在里面,下方是完整的代码
''' 请不要复制这部分,这个脚本会放在下方的CI文件运行,我手动复制了运行的方式 /usr/bin/gitlab-ai "$chat_id" "code_diff.txt" "$commit_sha" "$project_id" "$PREPROMPT" 制作成二进制文件请使用chmod +x gitlab-ai 添加可执行权限,并且放在/usr/bin/下,确保runner用户可以运行 ''' import requests import sys import os import time import uuid # gitlab服务配置 gitlab_http = "http://192.168.198.215" GITLAB_TOKEN = "1111111111111111111" # gitlab的token ,请确保token有api的权限 # open-webui用户信息 name = "shikai" # 这个配置没作用,可以移除 passwd = "my passwd" # 请输入open-wenui 的密码 email = "my email" # 请输入open-wenui 的登入用户就是邮件地址 MODEL = "llama3:8b" # AI 模型名称,本地安装什么模型就选择对应的 MODEL_HOST = "http://192.168.198.180:3000" # open-webui的访问地址 chat_id = "" messages = [] last = {} def post(url, headers, data): """发送 POST 请求""" response = requests.post(url, headers=headers, json=data) if response.status_code != 200: print('Error:', response.text) return response def signin(email, pwd): """登录并获取 token""" global token, token_type url = MODEL_HOST + "/api/v1/auths/signin" headers = { 'Content-Type': 'application/json', 'accept': 'application/json' } data = { "email": email, "password": pwd } response = post(url, headers, data) if response.status_code == 200: token = response.json()["token"] token_type = response.json()["token_type"] return token # 返回 token def newchat(preprompt, commit_sha): """创建或恢复聊天会话""" global chat_id, last, messages headers = { 'Authorization': 'Bearer ' + token, 'accept': 'application/json', 'Content-Type': 'application/json', } # 尝试恢复现有的聊天会话,如果 chatid.txt 文件存在 if os.path.exists("chatid.txt"): with open("chatid.txt", "r") as fs: chat_id = fs.read().strip() # 去除可能存在的空格或换行 # 查询是否已有该 chat_id url = MODEL_HOST + '/api/v1/chats/' + chat_id response = requests.get(url, headers=headers) if response.status_code == 200: jd = response.json() print(jd) messages = jd["chat"]['messages'] for one in messages: if one["id"] == jd["chat"]["history"]["currentId"]: last = one break print("loaded history len ", len(messages)) print("last one", last) else: chat_id = "" # 如果没有找到聊天记录,则清空 chat_id # 如果没有找到现有的会话,或者恢复失败,则创建新的会话 if chat_id == "": url = MODEL_HOST + '/api/v1/chats/new' # 使用 commit_sha 作为会话标题,避免重复创建 data = { "chat": { "title": commit_sha # 使用 commit_sha 作为标题 } } response = post(url, headers, data) if response.status_code == 200: chat_id = response.json()['id'] with open("chatid.txt", "w") as fs: fs.write(chat_id) # 继续进行聊天流程,首先发送 preprompt 信息 chat(preprompt, commit_sha) # 发送 preprompt # 然后再进行实际的 diff 内容 else: print("创建新聊天失败", response.text) else: # 更新聊天会话时保持使用 commit_sha 作为标题 url = MODEL_HOST + '/api/v1/chats/' + chat_id data = { "chat": { "title": commit_sha, # 这里设置 commit_sha 作为标题 "models": [MODEL], "history": { "messages": dict(zip([aa['id'] for aa in messages], messages)), "currentId": last["id"] }, "messages": messages, "params": {}, "files": [] } } response = post(url, headers, data) print("chat_id", chat_id) def chat(msg, commit_sha, preprompt=None): """与 AI 进行聊天,先发送 preprompt 信息,再发送实际消息""" # print("user", "->", msg) global last newid = str(uuid.uuid4()) # 先发送 preprompt 信息 if preprompt: # 创建 preprompt 消息 preprompt_message = { "id": newid, "parentId": None, # preprompt 是第一个消息 "childrenIds": [], "role": "user", "content": preprompt, # 发送 preprompt 信息 "timestamp": int(time.time()), "models": [MODEL] } messages.append(preprompt_message) last = preprompt_message # 将 preprompt 设置为当前消息 # 发送消息到 AI 服务 url = MODEL_HOST + '/ollama/api/chat' headers = { 'Authorization': 'Bearer ' + token, 'accept': 'application/json', 'Content-Type': 'application/json', } data = { "model": MODEL, "format": "markdown", # 强制设置为 Markdown 格式 "messages": [{"role": one["role"], "content": one["content"]} for one in messages], "chat_id": chat_id, "stream": False, "keep_alive": 0, "options": {}, "id": preprompt_message["id"] } print("Sending preprompt to Ollama:", data) response = post(url, headers, data) if response.status_code == 200: jd = response.json() print(jd['message']["role"], "->", jd['message']["content"]) else: print("Error sending preprompt:", response.text) # 然后发送实际的代码差异内容(msg) newid = str(uuid.uuid4()) # 生成新的消息 ID if last != {}: last["childrenIds"].append(newid) last = { "id": newid, "parentId": last["id"] if last != {} else None, "childrenIds": [], "role": "user", "content": msg, # 发送实际的 Git diff 内容 "timestamp": int(time.time()), "models": [MODEL] } messages.append(last) # 发送数据到 AI 服务 url = MODEL_HOST + '/ollama/api/chat' headers = { 'Authorization': 'Bearer ' + token, 'accept': 'application/json', 'Content-Type': 'application/json', } data = { "model": MODEL, "format": "markdown", # 强制设置为 Markdown 格式 "messages": [{"role": one["role"], "content": one["content"]} for one in messages], "chat_id": chat_id, "stream": False, "keep_alive": 0, "options": {}, "id": last["id"] } response = post(url, headers, data) if response.status_code == 200: jd = response.json() repmsg = jd['message'] print(repmsg["role"], "->", repmsg["content"]) newrep = { "parentId": last["id"], "id": str(uuid.uuid4()), "childrenIds": [], "role": repmsg["role"], "content": repmsg["content"], "model": MODEL, "modelName": MODEL, "modelIdx": 0, "userContext": None, "timestamp": int(time.time()), "done": True, "context": None, "info": { "total_duration": jd["total_duration"], "load_duration": jd["load_duration"], "prompt_eval_count": jd["prompt_eval_count"], "prompt_eval_duration": jd["prompt_eval_duration"], "eval_count": jd["eval_count"], "eval_duration": jd["eval_duration"] } } last["childrenIds"].append(newrep["id"]) last = newrep messages.append(last) # 更新 chat url = MODEL_HOST + '/api/v1/chats/' + chat_id data = { "chat": { "title": commit_sha, "models": [MODEL], "history": { "messages": dict(zip([aa['id'] for aa in messages], messages)), "currentId": last["id"] }, "messages": messages, "params": {}, "files": [] } } response = post(url, headers, data) return repmsg["content"] def analyze_diff_with_ai(diffs, preprompt, commit_sha, REPONSE_PROMPT): """ 使用 AI 服务逐个分析代码差异。 - diffs: 代码差异列表。 - preprompt: 全局上下文提示。 - response_prompt: 每段差异的附加提示。 """ global token token = signin(email, passwd) if not token: return "登录失败。" # 初始化聊天会话并设置 preprompt newchat(preprompt, commit_sha) results = [] # 保存 AI 返回的结果 for diff in diffs: # 转换每段差异并附加 response_prompt markdown = f"```diff\n{diff}\n```\n" if REPONSE_PROMPT: markdown += f"\n{REPONSE_PROMPT}\n" # 添加 response_prompt # 调用 AI 服务分析 result = chat(markdown, commit_sha) results.append(result) # 合并所有分析结果 return "\n\n".join(results) def post_comment_to_gitlab(commit_sha, project_id, analysis_result): """将 AI 分析结果作为评论发布到 GitLab""" url = f"http://192.168.198.215/api/v4/projects/{project_id}/repository/commits/{commit_sha}/comments" headers = { 'Private-Token': GITLAB_TOKEN, 'Content-Type': 'application/json' } data = { "note": f"AI分析结果:\n{analysis_result}" } response = post(url, headers, data) if response.status_code == 201: print("成功将 AI 分析结果发布为 GitLab 评论。") else: print("发布评论失败:", response.text) def get_code_diff(code_diff_file): """读取代码差异文件""" try: with open(code_diff_file, 'r', encoding="utf-8") as file: return file.read() except Exception as e: sys.exit(f"读取代码差异文件时出错:{e}") def split_diff_by_git(diff_text): """ 按照 'diff --git' 切割差异文件。 每段以 'diff --git' 开头,直到下一个 'diff --git' 或文件结尾。 """ parts = diff_text.split("diff --git") return [("diff --git" + part).strip() for part in parts if part.strip()] # 跳过空部分 def main(): """主流程""" if len(sys.argv) < 6: print("缺少参数。请提供 chat_id、code_diff_file、commit_sha、project_id 和 preprompt。") sys.exit(1) chat_id = sys.argv[1] # 从命令行参数获取 chat_id code_diff_file = sys.argv[2] # 从命令行参数获取代码差异文件路径 commit_sha = sys.argv[3] # 从命令行参数获取 commit_sha project_id = sys.argv[4] # 从命令行参数获取项目 ID preprompt = sys.argv[5] # 从命令行参数获取 preprompt REPONSE_PROMPT = sys.argv[6] if len(sys.argv) > 6 else "" # 读取并分析代码差异 diff_text = get_code_diff(code_diff_file) diffs = split_diff_by_git(diff_text) analysis_result = analyze_diff_with_ai(diffs, preprompt, commit_sha, REPONSE_PROMPT) post_comment_to_gitlab(commit_sha, project_id, analysis_result) if __name__ == "__main__": main()
下方是.gitlab-ci.yml,我是配置专用runner使用,避免多线程导致获取异常,该runner最大运行一个job,请关注下方注释,根据自己环境实际情况进行修改,
最终发送的结果是使用markdown的方式,使用string 的方式发送ollama会自己识别成markdown,导致发送的数据ollama接收不准确,会把每个差异的文件依次发送接收AI的反馈,把所有结果一次性在gitlab评论
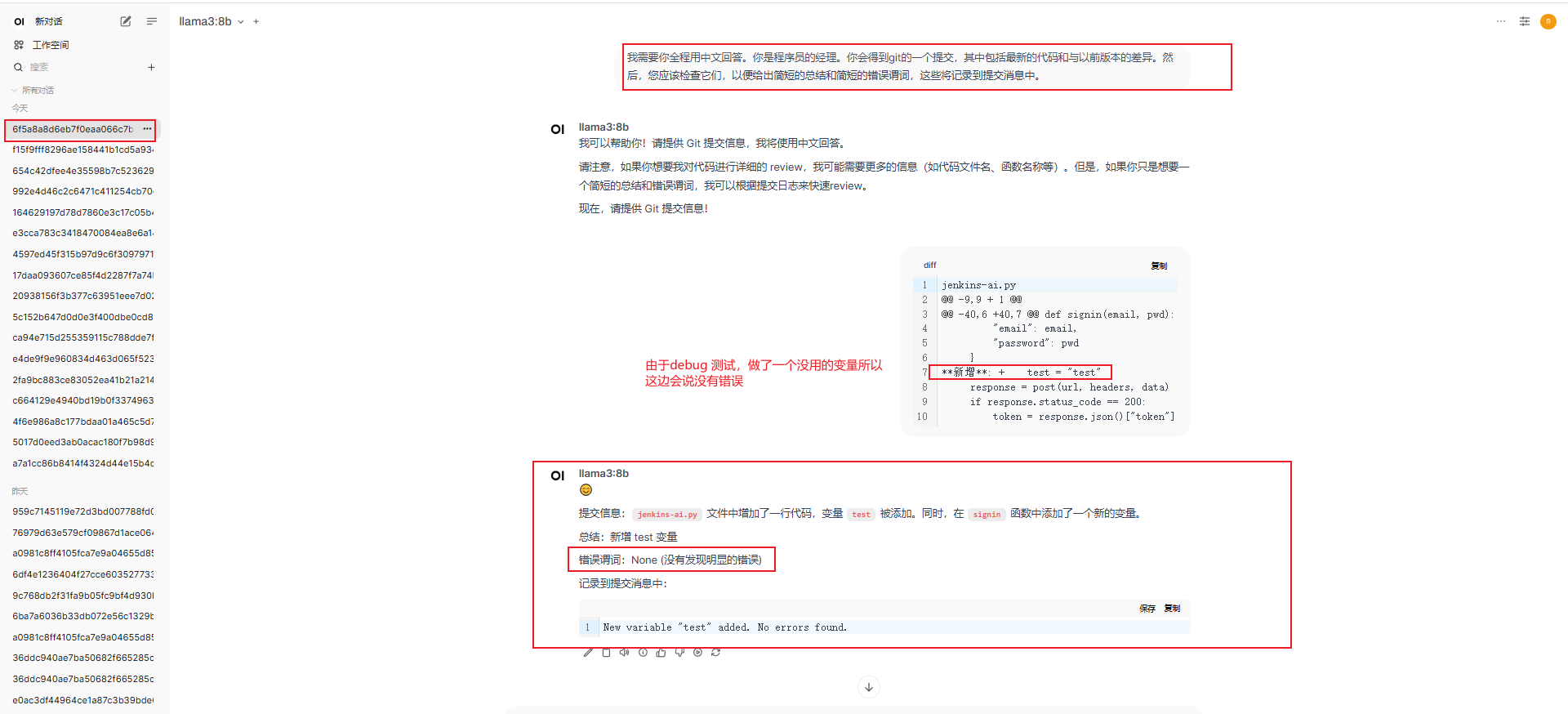
# 为了防止格式或其他意外错误,请删除文中所有的注释 shell: sed '/^\s*#/d' input_file > output_file stages: - analyze_diff # merge获取分支差异 - push_diff # 动作是push触发,建议这两个功能请二选一 variables: PROJECT_ID: "$CI_PROJECT_ID" PREPROMPT: "我需要你全程用中文回答。你是程序员的经理。你会得到git的一个提交,其中包括最新的代码和与以前版本的差异。然后,您应该检查它们,以便给出简短的总结和简短的错误谓词,这些将记录到提交消息中。" REPONSE_PROMPT: "只回顾有变化的函数。突出显示任何显著的变化,并识别潜在的风险或容易出错的区域。" # 这变量是会在markdown下方拼接发送提示AI GITLAB_API_TOKEN: "$CI_GITLAB_API_TOKEN" # 从 GitLab CI/CD Variables 获取 analyze_diff: stage: analyze_diff tags: - test180 # 执行runner-tag rules: - if: '$CI_PIPELINE_SOURCE == "merge_request_event"' # 判断如果是merge则触发这个tag when: always script: - | # 检查 MR 分支变量 if [ -z "$CI_MERGE_REQUEST_SOURCE_BRANCH_NAME" ] || [ -z "$CI_MERGE_REQUEST_TARGET_BRANCH_NAME" ]; then echo "Merge request branch names are not set. Exiting." exit 1 fi - git fetch origin $CI_MERGE_REQUEST_SOURCE_BRANCH_NAME $CI_MERGE_REQUEST_TARGET_BRANCH_NAME # 获取分支信息 - git diff -U50 origin/$CI_MERGE_REQUEST_TARGET_BRANCH_NAME..origin/$CI_MERGE_REQUEST_SOURCE_BRANCH_NAME -- '*.py' ':!test/' > analyze_code_diff.txt # 获取所有源提交与新合并的分支差异,获取上下50行这样AI好审核知道代码,以及后续指定.py文件,排除文件夹test以及文件夹里面的内容 - if [ ! -s analyze_code_diff.txt ]; then echo "No changes detected. Exiting."; exit 0; fi # 不满足条件主动退出 - export chat_id=$CI_PIPELINE_ID - export commit_sha=$CI_COMMIT_SHA - export project_id=$PROJECT_ID - /usr/bin/jenkins-ai "$chat_id" "analyze_code_diff.txt" "$commit_sha" "$project_id" "$PREPROMPT" push_diff: stage: push_diff tags: - test180 # runner-tag rules: - if: '$CI_PIPELINE_SOURCE == "push"' # 动作是push动作触发tag,这个触发频率过高不怎么建议使用这个 when: always script: - git fetch origin # 获取最新分支数据 - CHANGED_FILES=$(git diff --name-only HEAD~1 -- '*.go' '*.py' ':!*.md' ':!*.json') # 获取最新的提交与上一份提交的差异,以及排除文件或指定文件 - if [ -z "$CHANGED_FILES" ]; then echo "No matching files changed. Exiting."; exit 0; fi - > code_diff.txt # 预防文件有残留,手动清理 - | for file in $CHANGED_FILES; do echo "Processing file: $file" >> code_diff.txt git diff -U50 HEAD~1 -- "$file" >> code_diff.txt # 获取差异信息的上下50行 echo "" >> code_diff.txt done - export chat_id=$CI_PIPELINE_ID - export commit_sha=$CI_COMMIT_SHA - export project_id=$PROJECT_ID - /usr/bin/jenkins-ai "$chat_id" "code_diff.txt" "$commit_sha" "$project_id" "$PREPROMPT"下方全是效果展示
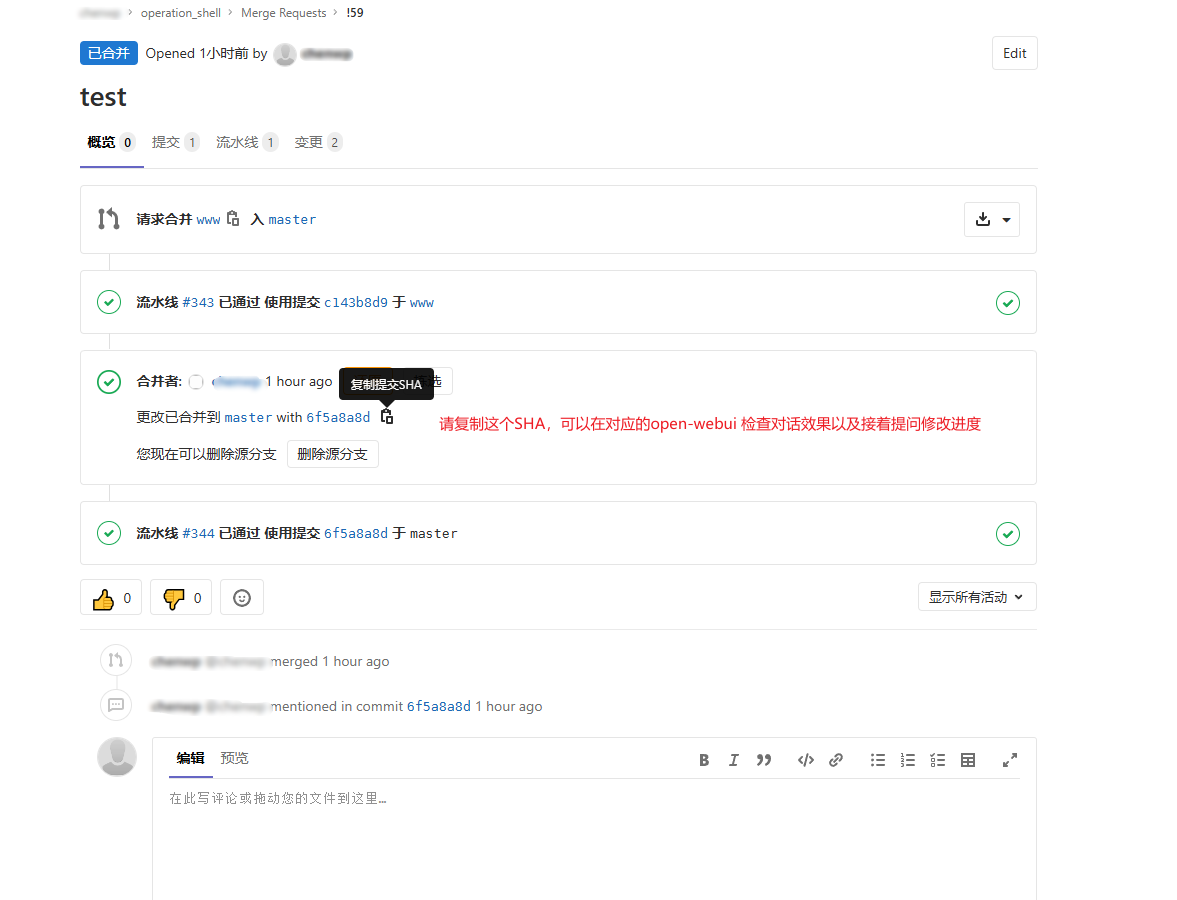
下方是runner运行图片